(Boy, they don't write manuals like that any
more!)
[This is currently in the process of being written, and at the moment is very disjointed; in fact there's at least one chapter that I'm very unhappy with and and am trying to come up with a good plan for a rewrite. I'm working bottom-up right now, adding chapters that I know will be needed, but without working them in to a coherent overall plan quite yet. So, this is not ready for release or publicity - and if I let anyone see it at all it'll be the readers of the compilers101 newsgroup from whom I'll be soliciting comments and advice...]
So what follows is a very condensed version of the book - all twenty chapters - written in a way that gives the main ideas but doesn't go into hands-on detail. Consider it the "Cliff Notes" version. Then it is followed by the same twenty chapters again, but expanded with lots of examples, and most importantly, with lots of exercises: the main idea behind this book is that we start with a simple exercise that any programmer should be able to do - write a calculator - and then we gradually add features to that calculator until eventually you discover that it has turned into a real compiler - without at any point ever having had to do anything particularly difficult or clever!
So you can decide from reading the short version in about 10 minutes whether you want to write a compiler, then you can work through the full version and actually write it. At any point while reading the short version in electronic format, you can click on links that will take you to the full version. When reading the full version, you can click on links that will take you out of the e-Book and into the actual source code.
We don't assume you have any advanced knowledge, but we do assume that you're smart enough to learn and that you're interested in learning. As far as programming skill is concerned, if you can write something no more complex than a simple calculator, you'll have no trouble writing a simple compiler with us. And before we start, we'll actually go over how to write a simple calculator, just to get you warmed up. (If you find the warm-up difficult, you'ld probably be doing yourself a favor by taking some basic programming classes first, then coming back here to learn about compilers. We don't assume a lot of experience but you really do need to be able to do basic programming already)
Obviously not all programmers are at the same level, and an advanced programmer doesn't want to be bogged down by beginner-level exercises, but a beginner similarly doesn't want to struggle with advanced coding; so the way we handle that here is to make sure that everyone who tackles writing a compiler by following this book manages to get something working that they can call a genuine compiler - but there will be optional chapters which you can take if you want to build a more advanced compiler with fancy code generation options and lots of optimisation - but the overall structure of the compiler that we'll have you build will be modular so that if you don't want to add the more advanced features, you'll still be able to write something that works. In fact the most basic compiler that we'll show you is something that even a beginner programmer should be able to finish in under a week.
And you can write your code in any language you like. Although the examples here may sometimes look like C, you don't need to be a C programmer to follow this book. You're welcome to write in Python, PERL, Ruby, PHP, Java, Javascript, LISP, ML, Logo, Pop2 - even Visual Basic. What's more, if you sign up for the Yahoo Group "compilers101" and show us your work as you progress through this book, we'll even take your code and put it online for other readers to look at. (If you're shy about letting people see your code, don't worry, it's not a necessity - but we're a gentle bunch and you'll learn a lot faster if you let people look at your code and offer their advice! There are not many books on compilers that come with a live person willing to give one-on-one help, so take advantage of it! :-) ) With any luck, after enough people have worked through this book using different implementation languages, we'll be able to point you to implementations in multiple languages.
Also, the language that your compiler accepts is not spelled out in this book. We'll show you general constructs but will leave the details to you. This isn't a university class and there is no benefit to you at all in just looking at someone else's solution. This book will only help you if you learn from it and write your own compiler. So its up to you to define the language you want to compile. It can be your own made-up language, or a language that someone else has defined, or your own - possibly cut-down - version of someone else's language. For the purpose of giving actual examples in the book rather than just hand-waving, we are going to use a subset of C for our target language, but it could equally be something that looks like Pascal or like Basic. The details really don't matter that much - all compilers have a great deal in common!
Inventing algorithms is pretty much just applying common sense. If you can explain the problem clearly, you can probably implement a working solution just from the problem description. Then you refine the solution step by step.
Once we have a decent operator precedence calculator working, we'll make it more useful by adding lots of different operators. For the worked examples, we'll use the operators from "C", but you can do the same thing with whatever language you prefer to work in, which will undoubtedly have a different set of operators and those will have different relative precedences from the "C" ones.
One of the things we'll add at this point is conditional operators - "and", "or". We'll implement these fairly simply, in the same way that we've done for "*" and "+".
We're deliberately only looking at binary operators for now. We'll look at unary operators (unary minus, logical not, etc) in the later chapter on parsing. Although they're easy to generate code for and you could do that right now, they're not so easy to parse, so we'll delay the code generation for those until after we've worked out how to parse them.
By now of course you've realised that our calculator is going to end up being our compiler. It's not going to spoil any surprises if I mention at this point that the next couple of things we're going to add to this programmable calculator are temporary storage variables (ever noticed a STO key on a scientific calculator?), and the ability to do loops and conditions.
Now, it would be more of a learning experience if you went ahead and tried to generate code for those things just to see how it looked, but unless we cover a couple of extra concepts first, I can tell you that it's going to be difficult. So I'll cheat a little and introduce something that you're going to need later, without really explaining why you're going to need it. But you'll be using this stuff pretty soon, and the reasons behind it will become obvious.
What we're going to add to our calculator in this chapter is reading the expression into memory first, then generating a data structure in memory representing the program that we want to create, and then we'll output the program...
extending bottom-up precedence parser to more than just exprs (everything is an operator... - see rainer. [] -> . () etc )
hybrid parser with bottom-up for exprs
Program-generated parser (use tacc as an example - extract language part from http://www.gtoal.com/compilers101/gtlanguage/language.e.html
and show generated procedures. Sidetrack about coverage testing)
Could be a good time to cover lexing vs line-reconstruction vs explicit spaces in the grammar (vs implicit spaces before (or better, after) tokens?)
dijkstra - application of bottom-up precedence technique *after* parsing
easy hack of flatten parse tree (remember '(' nodes however) vs building into the parser.
When describing AST implementation, show the trick with simple array of ints vs complex object-oriented structures and explain advantages, but don't discourage the reader from doing it the traditional way if they find that easier. Mention bootstrapping as a teaser for later.
Notes on AST -> CFG (& linearised code) (eg loops vs AST node containing while body) here or next chapter. Suggest similarities in the hierachy of structures as we go down the levels, and suggest radical idea that maybe the same structure can be used throughout!
Start with actual HP calculator notation, then P-Code, then some real hardware (KDF-9?). Show how you can use register-based machines in a stack mode, and why sometimes that may not be a bad idea.
Aside: walking the AST to generate a high-level representation - This is how we do pretty printing or language translation! (Needs minor tweak to store comments as decoration of lexed items - bypassing the grammar... more 'line reconstruction'. C is particularly bad, with issues involving CPP and token pasting.) Also known as 'unparsing'.
However, because we're generating code for a simple stack-based machine, we can't, right?
Actually we can, but there's an extra step involved. We just have to translate from our simple pretend machine to a real machine. That turns out to be pretty easy, because the pretend opcodes don't actually do anything very complicated. All we have to do is work out a sequence of real instructions that corresponds to each pretend instruction.
For example:
PUSH #1
PUSH #2
ADD
is pretty easy, especially since on the real machine we're going to use, there
already
exists a real 'push' instruction.
Using the freeware "netwide assembler" (aka "nasm"), the instructions for an X86 for the sequence above would be:
push dword 1 ; PUSH #1
push dword 2 ; PUSH #2
pop ecx ; ADD
pop eax
add ecx, eax
push ecx
So you can see that even though the code is a little larger (the ADD went from
one
instruction to four) it's not outrageously larger, and it would not be at all
impractical to compile an entire program with code of this quality.
And the neat thing is we don't even need to change our compiler to do this - we can macro-process our current output to expand from pretend opcodes to real ones! A suitable macro processor is included with this book: it's called "assemble", and generates code for the Intel X86 architecture. By using nasm, and gcc as our linker, the assembly code files that it generates are actually portable between both Windows and Linux. However if you want to run your code on some other architecture, such as an older Mac with a 68000 or PPC chip, you can make the changes to assemble.c to have it produce code for those chips too!
Interestingly enough, this technique of generating pretend instructions and then translating them to real instructions has been used in earnest many times in the past, particularly for bootstrapping compilers.
'bootstrapping' is what we call the process of making a compiler compile itself on a completely new architecture, where there is no existing compiler that can be used to port it. The early BCPL compiler (the grandfather of C) was built like this, as was Nicklaus Wirth's portable Pascal compiler - Wirth's pretend instruction set was called "P-Code" (Pascal Code) and spawned a generation of imitators! Modern Java implementations (based on the JVM byte code) are directly descended from this. So it might we worth bearing in mind at this point, that if you write your compiler using simple constructs, so that once it is working you can massage your compiler source a little to match your own language, you'll be able to compile your own compiler down to our stack-based instrcutions, then convert those to x86 instructions, compile them with nasm ... and have a version of your compiler that was compiled by itself!
If you are the sort of person who is more interested in good solid software-engineering and building reliable code, more than you are interested in trying out cool new algorithms, then I have a suggestion for you: just skip the chapters and exercises that follow, where we work on different kinds of code generators, and extend your language so that it covers enough constructs that it's possible to write a compiler in it. Get your compiler to the stage where it can compile itself, and do so using the stack machine and the macro-assembler that we supply. Come back to the following chapters once you're completely self-sufficient!
The rest of us will get there eventually, but first we'll look at different ways of generating code. We'll look at how to generate code for more complex architectures, we'll start using registers instead of a stack, and we'll generate code that runs a bit faster - maybe 3 to 4 times as fast - but the results of running your programs will be identical. In fact we'll be comparing results from both methods just to make sure that our compiler is generating sensible code!
Initially as a truly minor tweak to the stack code, using the node indexes as tmp variable nums. (If not using that kind of tree for the AST, you'll need to add explicit numbering to the nodes as a data field rather than an index)
Register allocation: parallel with stack depth. Tricks for minimising stack depth are same as for minimising register use. What to do when you run out of regs? Temporaries or explicit stack? (Temporaries. Explicit stack messes up when you do CSE later)
boolean expressions vs special-case conditionals (C vs Pascal); short-circuit evaluation (not really tied to implementation, wider language design issue)
Ties into early chapter on serialising the AST.Difference between AST and linear CFG/IR
Show the trick of only looking at the branch instructions, and keeping everything else as a monolithic chunk. In a Robertson compiler, that would be a chunk of compiled binary (done in pass 3) but in my compiler, it's a chunk of AST nodes, still to be compiled.
Compare the AST of declarations, to the corresponding AST from a usage - trees should match. Explain symbol tables. (Nested contexts? may be better to wait until after nested procedures) Code generation for array accesses, pointers, and record fields. Can be simplified by language design. (C is not simple). Bottom-up vs top-down type matching, type casting/coercion, and polymorphism - all language design issues.
Simple BCPL/C model vs algol/pascal nested procedures (which require the use of a Display)
Revisit symbol table handling, for nested blocks?
Pop2/forth model of explicit stack - worth implementing for us because very simple. (not subroutine return address stack)
Copy-in/copy-out vs call by address. (Leave call by name as a footnote)
Access to out-of-block variables? By address? - serious optimisation issues affected by language design (sidenote on functional languages)
Multiple function results? Same mechanism, eg
get_midpoint(xl, yb, xr, yt) -> xm, ym
get_index(whatever) -> i, element[i]
(just remember to have compiler check that no. of params match up, and you don't leave an unbalanced stack)
compiler writer as language designer - OK if for your own benefit, maybe not so cool if for other people - tend to be too influenced by compiler design. On the other hand language design without understanding compiler structure is worse! Best compromise is a reluctant compiler writer :-) Note nice compromises likes Pops reverse assignment, a + b => c... allows cool parsing tricks and mathematically nicer than an '=' which is not the 'equivalent' operator. (Mention C's nasty '==' vs '=' hack. And how other languages avoid it)
End the chapter with a formal definition of our 'extended calculator language'.
do some examples for intel. describe other architectures. Show threaded code/virtual stack machine vs 'real' code. Show how things like procedures to do I/O can clobber all your registers (but does it matter for I/O? It might matter however for a call to 'iexp()' ...*/
maybe examples from micros, video games?
Easy at either AST or triples stage (note generalization to n-tuples and neat implementation trick if using a flat array rather than structs)
Easy if at statement level only. Def/use. Compare triples. Tricky if across multiple statements. Ultra tricky if jump destinations between statements (CFGs and Phi-nodes... touch on this subject only lightly!).
Somewhere in this or the previous two chapters we need a sidenote on peepholing and why to avoid it except as a machine-specific back-end tweak. Show hierarchy of code as being a sequence of rewrites from concrete syntax -> abstract syntax -> CFG -> linear code -> SSA -> machine code, and put peepholing in a larger context as being the final level of rewrite rule application.
(Note the convenience of a 'REDIRECT' node rather than having to do a global renumbering/restructuring whenever a node is replaced. trivial to implement and avoids N^2 complexity. (I think I used this a lot in my static binary translator code? Need to check.))
Using existing tools (yacc, antlr, coco etc etc)
(Restricted to particular languages - use a different language, you may be without a tool...)
See http://www.gtoal.com/compilers101/gtlanguage/yaccdemo.[cl] for a calc-level language using yacc & lex.
Take the code generators from earlier exercises and add them to this parser.
Solutions in http://www.gtoal.com/compilers101/gtlanguage/lexyaccdemo/
See coco version of simple language in: http://www.gtoal.com/compilers101/gtlanguage/language.atg
Table-driven code generators? (iburg etc)
Learning advanced techniques (Munchkin)
Pointer to books. Other people's code.
Breaking old assumptions. Space/size/complexity/programmer time; Or how about storing variable names as strings - if the parser returns a list of characters, then why not keep strings as a list of characters? Avoid problems with string length checks, just as easy to compare, also allows a 'string' which is actually a tree of words - may be useful somewhere...
Chapter Zero: Introduction and sales pitch
If you've found your way to this book, it's a safe bet that
you're already a programmer and that you're the sort of person who wants to
learn new skills. If that's the case, you already have the pre-requisites
needed to learn how to write your first compiler by following this
book.
So what does "from first principles" mean in the title of this book?
Simply that we're going to work it all out ourselves through common sense and a bit of experimentation. I'm not going to feed you complicated ideas that someone else has come up with that you have to take on trust. Everything you do here will be something you understand completely because you worked it out for yourself. Yes, I'll steer you in the right direction, and give hints to help you if you get stuck, but I'm not going to spoon-feed you a sample solution! In fact you're going to do almost all of the coding yourself. If I supplied the code for a compiler, I might as well give you a copy of gcc to read. This book is about your first compiler, not mine!
The approach we're going to take is quite unlike any other compiler class that I'm aware of. I'm going to give you some simple programming exercises to do - starting with a really easy one that anyone who has already learned the basics of programming will be able to do in less than an hour, and we'll gradually add features to these trivial programs bit by bit so that at the end of the day you realise you've actually written a complete compiler and at no point was there ever anything difficult involved!
The big secret about compiler writing is that it is both fun and easy! If anyone tells you it's not easy, then they're going about it the wrong way.
Now, I will be completely honest with you up front and explain that once you have completed this book, you'll have written what is only a very simple compiler - probably about the level of complexity of the BASIC compiler that Bill Gates wrote which started off the whole Microsoft thing!
Most of the compilers you actually use at the moment will be far more complex than the one you'll write. However you will understand how a compiler works, and if you want to study more by the time you've got your first compiler working, you'll have a head and shoulders start over those people whose first experience of compiler writing is from a classic Computer Science textbook. (Trust me on this, I've read quite a few of them, and they're hard going!)
Here's a quick summary of what this book is about: the
central part of any compiler is the part that handles simple statements
that perform calculations, such as
interest = (principal * rate) / 100
You're making a calculation, and saving the results into a variable. Just doing that for various types of calculation is probably about 50% of what every program you have ever run does, so if we can write a compiler that does calculations, we're half way there, right? :-)
Well, performing calculations is also what a calculator does. So let's start by writing a calculator rather than a compiler. This is a first-year exercise and one I hope that you can do relatively easily. If you find writing a calculator difficult, it might be worth putting this book back on the shelf and picking up an intro to programming instead. You don't need any previous experience writing compilers to use this book, but you do need to know how to program already.
So we're going to start by writing a simple calculator. Then I'll show you how to modify the calculator so that instead of just performing the calculation, you generate code to perform the calculation.
And that'll actually be the hard bit done. After that it's all small tweaks - we'll add variables, so that you can feed one calculation into the next one; we'll add flow control (ifs, loops etc) so that you can make a different calculation depending on the result of a previous one; we'll throw in procedures and functions so that you don't need to type too much code; and ... damn, there's not much left to do! That's pretty much all there is in a compiler! I told you this was going to be easy... :-)
So enough hype, stop reading this in the bookshop and go buy it; the rest of the book is for reading when you can get to your computer and start programming!
Let's start by writing an interactive calculator program
where all it does is prompt for an expression, which you enter, and it
prints out the result. I'll assume we're using linux in these examples,
although apart from the command-line prompt, they'll be identical if you
write them in the Microsoft environment. I'm not going to tell you what
operating system to use, and you can program in any language you like.
That's one of the advantages of not spoon-feeding you a textbook solution!
What we will do is give trivial examples of code in a random
language we make up as we go along. Later you'll discover that the
language we're using for examples is the same language that your compiler
will accept, and at the end of the book you will have one of the best
experiences a programmer can have out of bed - you'll compile your own
compiler using your own compiler! It's a process we call 'bootstrapping'
and it is COOL!
So, here's our calculator program in action:
linux% ./stupid
Expression: 2 + 3 * 4
Answer = 20
What you're looking at here is a dumb calculator that
accepts infix notation but processes the expression from left to right,
i.e. as soon as it saw 2+3 it evaluated it to 5, then multiplying by 4 gave
the result of 20. In other words, it treated the expression as if it were
"((2 + 3) * 4)"
This is not a hard program to write. You need to go and code it up right now. Even if you think it is trivial and too easy for you, do it anyway - because we're going to build on this program as we add to our compiler.
OK, I assume you got that working OK. Now, that's not a great calculator because it doesn't give the answer you'ld normally expect for "2 + 3*4" (at least I hope you'ld expect 14!)
So we'll try writing a different style of calculator next. Back in the 60's when calculators were implemented with hardwired logic, Hewlett-Packard calculators were very popular with scientists because they allowed a way of handling calculations like "2 + 3 * 4" that didn't return the wrong result of "20"... (calculators with a "(" key were very scarce at first, and calculators that handled normal operator precedence rules just didn't exist for the first few years. By the time they did come out, a lot of people had grown accustomed to the strange HP way of working and indeed you'll still find some of these people around today!) Unfortunately you couldn't just key in "2 + 3 * 4" - you had to enter it as "2 3 4 * +" !
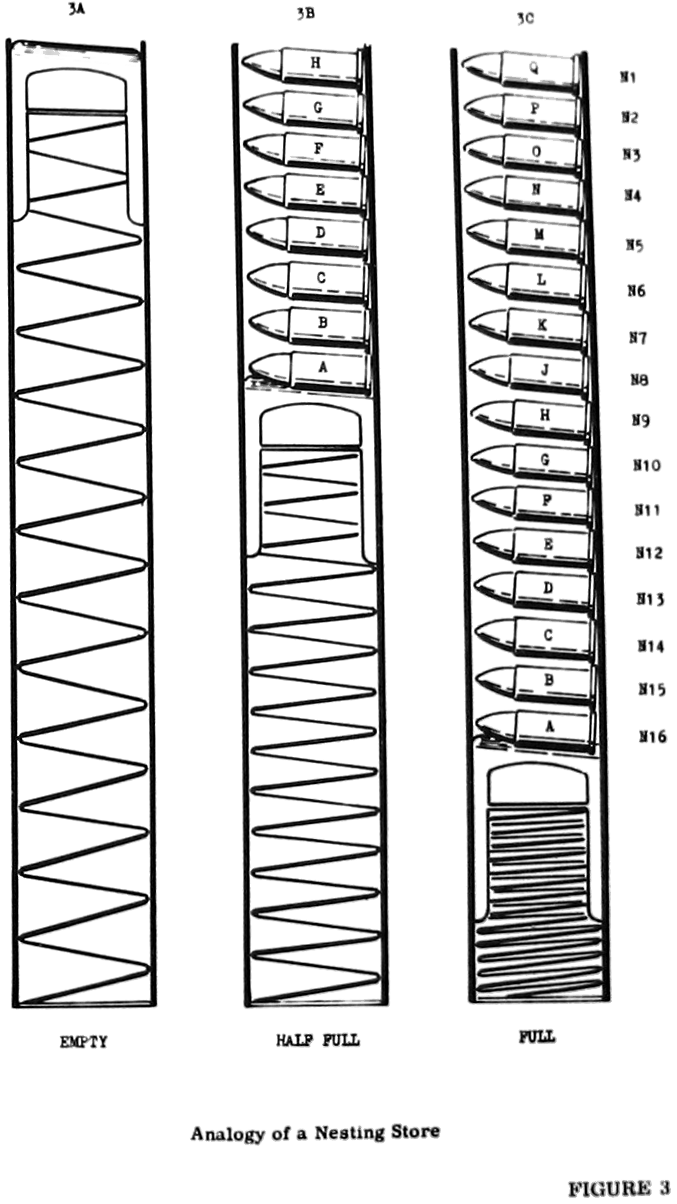
This bass-ackwards way of entering calculations was called "Reverse Polish", and it worked by using the concept that Computer Scientists call a stack. Here's a wonderful illustration from the 60's of how a stack works!:
(Boy, they don't write manuals like that any more!)
Let's go along with this metaphor and see how it would work using our example calculation...
Take 5 bullets and write the parts of the expression on them, i.e. "2" "+" "3" "*" "4"
We're going to fill the clip with these bullets, but we're going to follow this rule as we do so: if the next bullet to add has a number written on it, push it in. If it has an operator written on it, pull out the top two bullets from the clip, do the calculation in your head that comes from the two numbered bullets you just pulled out and the one you're holding that has the operator on it, then write the answer on another bullet and push it into the clip instead. (You can throw the other three away now. Safely of course!)
So we have to line up our bullets in this order: "2" "3" "4" "*" "+" (which if you haven't guessed is "Reverse Polish" order...)
We push down 2, then 3, then 4 into the clip, leaving "4" showing at the top.
The next bullet has a "*" on it, so we pop out "4" and "3" and in our heads we multiply 3 by 4. We throw those bullets away, write "12" on a new one, and push it back into the clip. The clip now contains "2" and "12" with the latter on top.
We pick up the last bullet and you'll see it has a "+" on it. So we pop out the two numbered bullets from the top of the clip and add them. "2" plus "12" is 14. We throw away the 2, the 12, and the "+" bullets, write "14" on a new one, and push it in the clip.
Now I guess we can fire our gun :-) and "14" will come shooting out the
sharp end... 14 of course is the answer we're looking for.
In computer science terminology, what I just described was a 'push-down stack' and the way we wrote the sequence of instructions ("2 3 4 * +") was 'Reverse Polish Notation'.
Now that you know all that (and the only reason I explained this in detail was to give me an excuse to use that wonderful drawing from the 1960's KDF9 Programming Manual !), you can write a reverse polish calculator instead of the simple left-to-right one, and get the correct result from our calculation...
It'll behave like this:
linux% ./revpol
Expression: 2 3 4 * +
Answer = 14
Your code for this should be trivial - when you read a number, just push it down on the stack, and when you read an operator, apply it to the top two items on the stack (or top item if it is a unary operator).
Your code will look something like this:
loop
say "Expression: "
read something
if something is '+'
Add()
if something is '*'
Multiply()
else if something is data
Push(something)
else if something is end of line
say "Answer = "
Print()
say "\n"
endif
endloop
You might find it useful to write some utility procedures at this point: I suggest writing Add() and Multiply() which will take the top two stack items, remove them from the stack, do the operation on them, and push the result back on the stack; Print() will just pop the top of the stack and print that value without pushing it back. You'll need a function Pop() which removes the top item from the stack and returns it as a result; and you might find it useful for later to add a function Dup() which pushes a copy of the top of the stack onto the stack (i.e. duplicate top-of-stack).
The code above will get tedious if you have a lot of operators, so consider writing a procedure "Operate()" which takes as the operator as a parameter. Your code might look something like this by now...
define Add()
return Pop() + Pop()
endproc
define Multiply()
return Pop() * Pop()
endproc
define operate(symbol)
if symbol is '+'
Add()
else if symbol is '*'
Multiply()
end if
endproc
loop
ask "Expression: "
read(something)
if something is an operator
operate(something)
else if something is data
push(something)
else if something is end of line
print("Answer = ", pop)
endif
endloop
Now having got the basics in place, the next step is to add a little parsing to the code:
linux% ./bracketcalc Expression: 2 + (3 * 4) Answer = 14
This is still very like the first calculator you wrote, as all it does is a simple left-to-right evaluation, but whenever you come across an expression inside brackets (eg "(3 * 4)") you need to handle whatever is inside the brackets as if it were a whole calculation in its own right and substitute the results in your expression before continuing with your left-to-right evaluation.
For example:
12
2 + (3 * 4)
Note the result of evaluating this expression:
linux% ./bracketcalc Expression: 2 + (3 * 4) * (5 + 6) Answer = 154
Because we're still doing left-to-right evaluation, the above is
equivalent to 2 + 12 * 11 which when calculated sequentially is 14 * 11 =
154. It's not 2 + ((3 * 4) 12 * (5 + 6) 11) = 134 as you might expect...
Before we leave this chapter, make sure you got these programs to run and give the expected results. If you didn't, you probably ought to take a break for a month and work on you programming skills. You won't need to be much more advanced than what's needed to write the two programs above, but if you're struggling with the intro exercises, it's probably asking too much to expect you to follow the rest of this book.
Roll up, roll up, roll up! We're going to perform a magic trick that turns your calculator into a compiler!
This trick is really cool because you can do this without writing almost any code, and it will work for any of the simple calculators you just wrote and it will also work for the slightly fancier one we're going to handle in Chapter 3. We'll see how in a minute.
The first compiler we're going to make will be an incredibly simple compiler that only generates code for expressions.
Our target computer will be the Hewlett-Packard scientific calculator that I mentioned when I gave you a quick run-down of Reverse Polish notation.
Since we can't actually load binary code into this calculator, we're just going to print out on a piece of paper a sequence of instructions for a user to key in that will execute our calculation on the calculator.
Your Multiply() procedure in this case would now look like this:
define Multiply say "MULTIPLY" endproc
In other words instead of performing the calculations, you just print out the instructions and tell someone else to perform the calculations.
The output I would expect to see for our favorite calculation would now be something like this:
2 ENTER 3 ENTER 4 ENTER MULTIPLY ADD
Keying in a number on this calculator and pressing the ENTER button pushes it on the stack.
Pressing an operator key replaces the top two items on the stack with the result of performing that operation on them.
The '=' key causes the result (held in the top of the stack) to be popped from the top of the stack and shown on the 7-segment LED display!
And since you probably don't own a real HP reverse-polish scientific calculator, you can test this by writing code that does almost the same thing:
Push(2); Push(3); Push(4); Multiply(); Add(); Print();
And by an amazing stroke of luck, we just happen to have these exact procedures written already, from when we wrote the reverse-Polish calculator! So what you'll be doing is writing a program that generates another program very similar to the revpol calculator, except where before you had code to read in the expression and calculate it, in this version you'll only have the code to perform the one-off calculation.
Guess what? You just wrote a compiler and an emulator! Damn, you're good!
Now... the final step... you need to work out how to do operator precedence on your expressions, so that you get the answer you really expected in the first place:
linux% ./prec Expression: 2 + 3 * 4 Answer = 14
I'm not going to explain (yet) how to do operator precedence, and I don't want you to look it up either. The problem can be worked out from first principles by an ordinary person, you don't have to be a Dijkstra or a Knuth :-) Just think back to when you were 5 or 6 years old and were being taught 'sums' for the first time. Did your teacher explain about multiplying and dividing being more important than adding and subtracting? How did she show you to do sums with paper and a pencil?
I don't want you to write code at this point, but I want you to explain in language a 5yr old would understand, how to do sums that mix '*' and '+' ...
The next chapter will go over the answer, and help you work out an algorithm from first principles - but you'll still have to write the code yourself!
You know, this may possibly have been the shortest chapter of any book I've ever seen.
Here's where the fun starts. Yes, I really am going to talk to you like a 5 year old!
Write down your sum:
2 + 3 * 4
What's more important, the "+" or the "*"?
"Please miss, it's the 'times'!"
OK, let's do that sum first! Score out 3*4 and write in what it's equal to:
12
2 + 3 * 4
So what does your sum look like now, children?
2 + 12
OK, is that difficult?
"No miss!"
Well, write down the answer!
14
OK, that's enough treating you like a 5yr old. You get the picture. To handle operator precedence, you look at your entire calculation and do the most important bit first. It's just the same as bracketed calculations - just do the part in the brackets first. And if the brackets contain other brackets, do them first instead.
Turning this simple rule ("so simple a child could do it") into a program is not that much harder than writing the code you already wrote to handle brackets.
Hopefully this was enough of a hint to let you work out an algorithm for yourself. You'll understand the problem a lot better if you stop reading now, and go try to write code to implement what our schoolteacher just explained above. Even if you get it wrong, you'll understand the problem better.
Once you've given it your best try, come back and read Chapter 5. I'll break my own rule just this once and spell out how to do operator precedence the easy way. I warn you that I'm not going to be so generous later!
(Here's another attempt at the above, and it's just as badly written :-/ this line of development isn't working for me and I think I need to go off and come up with something different.)
Some time back in '64 or '65, my Primary School teacher, Mrs Davidson, taught us how to do sums. I think the first year was simple arithmetic and counting using coloured wooden blocks, but by the second year we were doing pretty complex expressions on paper (or more often on a chalk board - the PDA of its day...)
I'll try to remember how Mrs Davidson taught us about the significance of multiply and divide being greater than that of add and subtract. By this point we had already covered using brackets to describe subexpressions, and she had just explained to us that multiply was 'more important' than 'add', so that 2 + 3 * 4 was actually 14 and not 20. This class went on to show that the same rule applied no matter how big the sum...
Later note: they still teach this the same way - here's a current example: http://www.mathsisfun.com/operation-order-pemdas.html - this calculator gives a good graphical example… Note however that exponentiation is right to left (eg 2^2^2^2) which I don't think is explained at the web page.Children, write down this sum on your boards.
1 + 2 + 3 * 4 * 5 + 6 * 7 + 8 + 9
Now, read along it from left to right, passing over all additions and subtractions until you come to a multiply or divide sign. Underline everything you've skipped past.
1 + 2 + 3 * 4 * 5 + 6 * 7 + 8 + 9
Oops, I didn't describe that very well. I meant for you to stop before the number that comes before the first multiply or divide sign.
1 + 2 + 3 * 4 * 5 + 6 * 7 + 8 + 9
That's it! Now do the same thing for all the numbers that are multiplied together and stop when you run out of things to multiply or divide:
1 + 2 + 3 * 4 * 5 + 6 * 7 + 8 + 9
Keep doing the same thing to the very end...
1 + 2 + 3 * 4 * 5 + 6 * 7 + 8 + 9
Now, work out each of the sums that is underlined, and rub them out and write in the answer in their place.
3 + 60 + 42 + 17
And finally add them all up
122
Good class! Now we're going to add a new operation called 'to the power of' which we'll write like this: 5 ^ 2 means 5 to the power of 2, or 5 squared - which as you know is equal to 25.
'to the power of' is even more important than multiply or divide, and it always gets done first. Here's another sum, and I'll show you how to do this one:
1 + 2 + 3 * 4 ^ 3 + 6 * 7 + 8 ^ 2
Underline the groups of numbers, and remember that ^ has a group now too.
1 + 2 + 3 * 4 ^ 3 + 6 * 7 + 8 ^ 2
1 + 2 + 3 * 4 ^ 3 + 6 * 7 + 8 ^ 2
...
1 + 2 + 3 * 4 ^ 3 + 6 * 7 + 8 ^ 2
Now work out the underlined parts and replace the answers.
3 + 3 * 64 + 42 + 64
Alright, now do the same process again:
3 + 3 * 64 + 42 + 64
3 + 192 + 106
and your answer is:
301
Well, that's enough kids stuff. We know that the process above was equivalent to adding brackets, and we probably wouldn't take multiple passes across the data to work it out.
I'll do that last example again but using brackets this time:
1 + 2 + 3 * 4 ^ 3 + 6 * 7 + 8 ^ 2
Put brackets round the operators with the highest precedence:
1 + 2 + 3 * (4 ^ 3) + 6 * 7 + (8 ^ 2)
and then the next level:
1 + 2 + (3 * (4 ^ 3)) + (6 * 7) + (8 ^ 2)
and finally we collapse the brackets from the inside out
1 + 2 + (3 * 64) + (6 * 7) + 64
and next
1 + 2 + 192 + 42 + 64
resulting in
301
So... in terms of a computer algorithm, let's work out what's important...
well, it's obvious when you get a sequence of more than one operator at the same level, that you can do the operations on the initial ones and just keep the last ones around in order to make the decision as to what to do next, eg:
1 + 2 + 3 + 4 + 5 * ...
can always be collapsed to
(1 + 2 + 3 + 4) + 5 * ...
ie
10 + 5 * ...
and similarly for any higher precedence operators that follow
10 + 5 * 6 * 7 ^ ...
can safely become
10 + (5 * 6) * 7 ^ ...
or
10 + 30 * 7 ^ ...
So we know how to handle the transition from a lower precedence to a higher one, but what about when the precedence drops again to something lower? well, let's look at that:
1 + 2 * 3 ^ 4 * 5 + 6
As soon as we see the "* 5" we know that the nested subexpression 3 ^ 4 can be collapsed:
1 + 2 * 81 * 5 + 6
and when we get to the "+ 6" we can collapse the preceding "2 * 81 * 5" ...
1 + 960 + 6
giving us the final result of
967
So the rule here is that if we hit a lower-precedence operator, we collapse the preceding expression until we get to the same precedence level as the operator we just examined.
Which brings us back to the same template as before, i.e. A + B * C ^ D ..., so all we have to really handle is that case. We can do that fairly easily with a simple stack that is no deeper than the number of precedence levels we need. The stack can either hold two types of object (data and operators) or we can have two parallel stacks where one holds the variables and the other holds the operators, eg something like this:
+ * ^
A B C
It's not really two stacks, it's actually one stack holding pairs of values (A, "+"), (B, "*"), (C, "^") (the 'D' is the next operand to be read, it doesn't need to be pushed)
So what we need to keep track of for this algorithm is the depth of the stack, and the precedence of the operators on the stack, and the precedence of the operator we're reading.
I think the description above - albeit somewhat lengthy - is sufficient to write the operator precedence code.
(OK, that's the end of the chapter on precedence which I've decided to rewrite. Meanwhile I'll start adding a few snippets of the following chapters - at this point I'm writing in a bottom-up way, putting down in print the sections I know we're going to need, but without yet having drawn them together into a coherent narrative. i did warn you at the start that this document is very much under construction... however I thought it was valuable to do the construction in the public view rather than work on it in private, and if any of our compilers101 members want to contribute, please email me and I'll give you write-access to this file...)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define TOK_NUMBER 1
#define TOK_VARIABLE 2
#define TOK_OPERATOR 3
#define TOK_WHITESPACE 4
#define TOK_NEWLINE 5
#define TOK_EOF 6
#define OPERATORS "+-*/^"
static int toktype[256]; /* all default to 0 */
char *get_tok(void)
{
static char buff[128]; // TODO: remember to add length check later
static int pend = -2;
int initc, c;
char *s = buff;
c = initc = (pend >= -1 ? pend : getchar()); pend = -2;
if (c != EOF) {
for (;;) {
if (isalpha(c) && islower(c)) c = toupper(c);
*s++ = c;
c = getchar();
if ((!isalpha(c) && !isdigit(c)) || (toktype[c] != toktype[initc])) break;
}
pend = c;
}
*s = '\0';
return strdup(buff);
}
char *op[4];
int top = -1, nest = -1;
void operate(char *op)
{
char *s;
switch (*op) {
case '+': s = "ADD"; break;
case '-': s = "SUB"; break;
case '*': s = "MUL"; break;
case '/': s = "DIV"; break;
case '^': s = "EXP"; break;
default: fprintf(stderr, "Bad operator %s\n", op); exit(1);
}
fprintf(stdout, " %s\n", s);
}
void operand(char *s) {
if ((nest+1 > 0) && (top != nest)) {fprintf(stderr, "Missing operator before %s\n", s); exit(1);}
nest += 1;
fprintf(stdout, " PUSH%s%s\n", (isdigit(*s) ? " #":" "), s);
}
void operator(char *s) {
if (top+1 != nest) {
if (top < 0) {
fprintf(stderr, "Missing initial operand before %s\n", s);
} else {
fprintf(stderr, "Missing operand between %s and %s\n", op[top], s);
}
exit(1);
}
// RULE 2: a * b + c => (a*b) + c ... do it before we push the next operand
while ((top > 0) && (prec(op[top]) > prec(s))) {
// stack is now just ... + a*b
nest -= 1; /* pop 2 operands, push 1 */
operate(op[top--]);
}
// RULE 1: a + b + c => (a+b) + c ... do it before we push the next operand
if ((top >= 0) && (prec(op[top]) == prec(s))) {
// stack is now just a + b
nest -= 1; /* pop 2 operands, push 1 */
operate(op[top--]);
}
op[++top] = s;
}
void evaluate(void) {
if (nest <0 && top < 0) return; /* nothing entered */
if (nest == top) {fprintf(stderr, "Missing operand after final %s\n", op[top]); exit(1);}
while (top >= 0) {
operate(op[top--]);
}
fprintf(stdout, " PRINT\n");
nest = top = -1;
}
int prec(char *op) {
return (strchr(OPERATORS, *op)-OPERATORS)/2; /* slightly hacky tweak for '+'='-' and '*'='/' */
}
int main(int argc, char **argv)
{
char *tok, *s;
int i;
toktype[0] = TOK_EOF; toktype['\n'] = TOK_NEWLINE;
toktype[' '] = TOK_WHITESPACE; toktype['\t'] = TOK_WHITESPACE;
for (i = 'A'; i <= 'Z'; i++) toktype[i] = TOK_VARIABLE;
for (i = '0'; i <= '9'; i++) toktype[i] = TOK_NUMBER;
for (s = OPERATORS; *s != '\0'; s++) toktype[*s] = TOK_OPERATOR;
for (;;) {
tok = get_tok();
switch (toktype[*tok]) {
case TOK_NUMBER:
operand(tok);
break;
case TOK_VARIABLE:
operand(tok);
break;
case TOK_OPERATOR:
operator(tok);
break;
case TOK_WHITESPACE:
continue;
case TOK_NEWLINE:
evaluate();
break;
case TOK_EOF:
evaluate();
exit(0);
default:
fprintf(stderr, "Bad character in input: %s\n", tok);
exit(1);
}
}
exit(0);
return(0);
}
Show how to use a tree structure to hold the expression before evaluating, rather than evaluating on the fly. need to come up with a good justification of why this is needed at this point (we know that the real reason is because it's needed for a real compiler, but truthfully, probably overkill for a calculator). maybe adding loops is a good enough justification? (but can't add loops until we add conditionals!)
extending bottom-up precedence parser to more than just exprs (everything is an operator... - Rainer Thonnes wrote a good demo on compilers101 which parsed [] -> . () and other constructs as operators - infix, postfix, prefix and mixfix! )
hybrid parser with bottom-up for exprs
Program-generated parser (use tacc as an example - extract language part from http://www.gtoal.com/compilers101/gtlanguage/language.e.html
and show generated procedures. Sidetrack about coverage testing)
Could be a good time to cover lexing vs line-reconstruction vs explicit spaces in the grammar (vs implicit spaces before (or better, after) tokens?)
dijkstra - the shunting yard algorithm is really just the application of bottom-up precedence technique *after* parsing
easy hack of flatten parse tree (remember '(' nodes however) vs building into the parser.
When describing AST implementation, show the trick with simple array of ints vs complex object-oriented structures and explain advantages, but don't discourage the reader from doing it the traditional way if they find that easier. Mention bootstrapping as a teaser for later.
Notes on AST -> CFG (& linearised code) (eg loops vs AST node containing while body) here or next chapter. Suggest similarities in the hierachy of structures as we go down the levels, and suggest radical idea that maybe the same structure can be used throughout!

Start with actual HP calculator notation, then P-Code, then some real hardware (KDF-9?). Show how you can use register-based machines in a stack mode, and why sometimes that may not be a bad idea.
Aside: walking the AST to generate a high-level representation - This is how we do pretty printing or language translation! (Needs minor tweak to store comments as decoration of lexed items - bypassing the grammar... more 'line reconstruction'. C is particularly bad, with issues involving CPP and token pasting.) Also known as 'unparsing'.
Trivial modification to stack machine.
Sidetrack into bignums, rationals. Show how easy it is to defer the decision!
Initially as a truly minor tweak to the stack code, using the node indexes as tmp variable nums. (If not using that kind of tree for the AST, you'll need to add explicit numbering to the nodes as a data field rather than an index)
Register allocation: parallel with stack depth. Tricks for minimising stack depth are same as for minimising register use. What to do when you run out of regs? Temporaries or explicit stack? (Temporaries. Explicit stack messes up when you do CSE later)
boolean expressions vs special-case conditionals (C vs Pascal); short-circuit evaluation (not really tied to implementation, wider language design issue)
Difference between AST and linear CFG
Compare AST for declaration to AST for usage - trees should match. Explain symbol tables. (Nested contexts? may be better to wait until after nested procedures) Code generation for array accesses, pointers, and record fields. Can be simplified by language design. (C is not simple)
Simple BCPL/C model vs algol/pascal nested procedures
Revisit symbol table handling, for nested blocks?
Pop2/forth model of explicit stack - worth implementing for us because very simple. (not subroutine return address stack)
Copy-in/copy-out vs call by address. (Leave call by name as a footnote)
Access to out-of-block variables? By address? - serious optimisation issues affected by language design (sidenote on functional languages)
Multiple function results? Same mechanism, eg
get_midpoint(xl, yb, xr, yt) -> xm, ym
get_index(whatever) -> i, element[i]
(just remember to have compiler check that no. of params match up, and you don't leave an unbalanced stack)
compiler writer as language designer - OK if for your own benefit, maybe not so cool if for other people - tend to be too influenced by compiler design. On the other hand language design without understanding compiler structure is worse! Best compromise is a reluctant compiler writer :-) Note nice compromises likes Pops reverse assignment, a + b => c... allows cool parsing tricks and mathematically nicer than an '=' which is not the 'equivalent' operator. (Mention C's nasty '==' vs '=' hack. And how other languages avoid it)
End the chapter with a formal definition of our 'extended calculator language'.
do some examples for intel. describe other architectures. Show threaded code/virtual stack machine vs 'real' code. Show how things like procedures to do I/O can clobber all your registers (but does it matter for I/O? It might matter however for a call to 'iexp()' ...*/
maybe examples from micros, video games?
Easy at either AST or triples stage
Easy if at statement level only. Def/use. Compare triples. Tricky if across multiple statements. Ultra tricky if jump destinations between statements (CFGs and Phi-nodes... touch on this subject only lightly!).
Somewhere in this or the previous two chapters we need a sidenote on peepholing and why to avoid it except as a machine-specific back-end tweak. Show hierarchy of code as being a sequence of rewrites from concrete syntax -> abstract syntax -> CFG -> linear code -> SSA -> machine code, and put peepholing in a larger context as being the final level of rewrite rule application.
(Note the convenience of a 'REDIRECT' node rather than having to do a global renumbering/restructuring whenever a node is replaced. trivial to implement and avoids N^2 complexity. (I think I used this a lot in my static binary translator code? Need to check.))
Using existing tools (yacc, antlr, coco etc etc)
(Restricted to particular languages - use a different language, you may be without a tool...)
See http://www.gtoal.com/compilers101/gtlanguage/yaccdemo.[cl] for a calc-level language using yacc & lex.
Take the code generators from earlier exercises and add them to this parser.
Solutions in http://www.gtoal.com/compilers101/gtlanguage/lexyaccdemo/
See coco version of simple language in: http://www.gtoal.com/compilers101/gtlanguage/language.atg
Table-driven code generators? (iburg etc)
Learning advanced techniques (Munchkin)
Pointer to books. Other people's code.
Breaking old assumptions. Space/size/complexity/programmer time; Or how about storing variable names as strings - if the parser returns a list of characters, then why not keep strings as a list of characters? Avoid problems with string length checks, just as easy to compare, also allows a 'string' which is actually a tree of words - may be useful somewhere...