{kind=link}

The algorithm described in this paper, which I will call "Global Analysis", and Monte Carlo Sampling, are both techniques for evaluating your opponent's possible replies to a selection of words you are contemplating playing.
Monte Carlo is the process of picking a rack at random and playing a word with it, which is repeated for sufficient racks such that the results are statistically significant.
Global Analysis is making one play, but holding in your rack every single unseen tile that is left, giving you a wide choice of reply. The replies include every single reply that any one rack could offer.
The main difference is this: In Monte Carlo, you work out for any given rack, what is the highest score you can get from that rack; In Global Analysis, you work out for any given highest score, which racks can attain that score. This reversal of the problem allows one slightly more expensive evaluation function to replace the thousands of evaluations necessary to get a statistically valid Monte Carlo sampling, because after the one global analysis, you have complete knowlege of the probabilities of all plays.
Having found the probability of each individual play (which is to say, for a 10 point play, we add up all the probabilities of all plays that we found which were worth 10 points), we can plot a cumulative frequency graph of 'score' versus 'probability of making that score, or more', eg (in tabular form):
score > 0 100% score > 5 99% score > 10 87% score > 20 58% score > 30 30% score > 50 10% ... score > 100 1%Using this, and a pre-determined cut-off point of 'acceptable risk', we can make a judgement such as "we expect this play to allow our opponent to make a score of no better than 25, and we'll ignore the risk that he might make more than that".
We do this for all of our plays, and use one level of minimax to chose our preferred play. It may be that this form of evaluation finally allows more than one level of lookahead (I'm told that in current Monte Carlo evaluators, the lookahead in the mid game is only one ply; deeper searches are used only near the endgame), but for now to keep the testing simple I will implement only one level of lookahead.
I've recently been corrected in my assumption of what current programs do; it is not MiniMax, though it does drill down to more than one ply. Here is how it was explained to me by Mark Watkins: Take two candidate moves A and B. For each candidate, generate a 4-ply sequence of moves, A1-A2-A3-A4 and B1-B2-B3-B4. Each move Ax/Bx is derived from a random rack (or rack fill) and one movegen and static eval. So with 8 movegens I have one 4-ply iteration for each move. Now do 20000 iterations. Then we have done 20000 4-ply sims.
I have currently successfully done the first part of a global evaluation of a board in mid-play (53 tiles left to draw, including both blanks). Most importantly, this took merely a few seconds to run - it was not a computationally expensive task, and annotating the moves with their probabilities is essentially free in comparison to generating the moves. [Here is a program to calculate rack probabilities which I wrote recently for other purposes]
Note: an upper limit of complexity for this style of evaluation would be this: imagine an entirely empty board. On the first row of that board, you can play any of the 15-letter words at 1A across. You can play any of the 14-letter words at 1A and 1B across. And so on, down to 2-letter words at 1A through 14A across. This is repeated for all 15 rows, and doubled to include vertical plays. So if we call W(X) the function which is the the count of the number of words in the dictionary of size X, then the maximum number of words to be evaluated can not possibly exceed [1*W(15) + 2*W(14) + 3*W(13) + ... + 13 * W(3) + 14 * W(2)] * 15 * 2. (I'll supply values for W(x) soon, when I have a chance to count up the words in the official tournament wordlist) I believe that when we count up the numbers (or run a board generation using these parameters) we'll probably find that a universal and exhaustive board generation can be done in some medium scale and finite number of seconds that is within the limit allowed for a move under tournament conditions, leaving sufficient time for the analysis of the results and perhaps another half ply of lookahead.
I was not sure at the outset if including the blanks in these calculations would make them considerably more difficult or not, so I generated the play list both with and without the blanks (they're about 1/4Mb each - here are the moves which require blanks - I love the 'SAXITOXINS' play!); it turns out that including the blanks in the analysis did not make it any significantly more complex. (Note in a real game these large lists of words would just be evaluated, not printed. The lists are for debugging only and to get a feel for the algorithm.) The 'with blanks' playlist here includes *EVERY* possible play with any combination of the unseen tiles not on the board.
Here is a condensed version of the playlist, more suitable for use as a report for humans in an analysis of the game; also please note where large numbers of options have been replaced with "???????" strings. In a lookahead evaluation, these wild-card strings would actually be placed on the board as if they were words, and the response to those moves evaluated. Each entry in this shortened file would be evaluated at the next ply. This is effectively an exhaustive next ply, compared to that of a Monte Carlo lookahead, which would have many more evaluations to compute yet cover fewer plays. (There is more on the idea of playing wild card tiles onto the board later in this document).
A useful diagnostic tool I'm working on with the help of
Kevin Cowtan is a graphic summary
of the condensed version of the playlist - the more times a tile can be placed on a square,
the darker it can be coloured. If there's only a handful of plays
on some particular area (eg the SAX -> SAXITOXIN(S) / SAXTUBA(S) extension) then
they'll show up only slightly tinted from the normal background
square colour. This will immediately show to a human where the
dangerous areas of the board are, and may well be a useful
study tool as well as being helpful in code design. Any squares
which are forced (see the -AL/AZO comment immediately below) could have the
letter inserted in the display in grey. (Another example is "DITAS"
which is the only play possible through DITA) - the S could be
indicated) [ADDENDUM: This code is currently being written;
Kevin Cowtan has already produced the
graphics generator and I'm
following up with the layout code as fast as I can.]
At the moment, I think that this diagram is showing promise, but
needs some modifications to be useful. The first modification is that
it should be separated into two diagrams, one for horizontal moves,
and one for vertical moves. Then - if possible - I'd like to partition
those diagrams such that each one was split up into a minimum number
of diagrams, displaying non-overlapping sets of plays. For example,
in the diagram below, there are a set of plays starting at 11B horizontally
which overlap with some plays which start at 11K horizontally. It would
be nice to keep them separate, without needing a different display for
every single play. (This is a knapsack problem I'm afraid, but a small
one and first-fit is probably going to be good enough as an approximation)
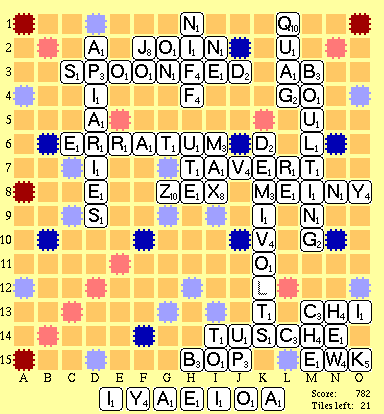
Jim Geary has pointed out that the information which this search generates also allows you to determine a good rack-leave on a play-by-play basis! For instance on the board below, you can make a 7-letter play at F7 down, as long as it ends in A (to make AZO across). Hence if you are not playing in that slot this move, A is a good rack leave. (I'm not doing Jim's suggestion justice with this grossly oversimplified example by the way; he really meant something a bit more sophisticated involving recalculations of the equity of the various letters, and synergy calculations of how well one letter can be paired with another)
Having thought about a way to implement what Jim suggested, I have come up with this: it is not quite what he envisioned but I hope has the same effect or better: I believe the result of a static evaluation can be used to calculate relative rack-leave values for each proposed play: the trick is not to look at the tiles you are left holding, but the tiles you need to pick up!Let's say there are 5000 words that can be played next. One of those words is 'retains'. I am left holding 'rt'. The probability of me picking a rack which allows 'retains' is the probability of me picking 'rt' (i.e. 1.0) times the probability of me picking up 'aeins'. If I do this for every word that can be played, and add up the probabilities of picking up an appropriate rack to complete each play, I have the value of holding 'rt' ...
It doesn't just work for 7's of course. If one of the words to be played is 'rain', then I have the 'r', I can't use the 't', and I have a certain probability of picking up 'ain' from the 5 tiles I will pick. Again, a cheap equation to compute. The formula for making these calculations also takes care of things like duplicated letters.
In fact I think this technique works even better for rack leaves of 5 or 6 tiles than for small racks, which is complimentary to the existing rack leave heuristics which work best for small leaves. Ask yourself what's the probability of picking 'ea' to a rack of 'inort' versus picking 'qu' to a rack of 'etzal'? - the figures that will come out for small draws will show more variation than large ones (which will average out more), thus making the choices more clear.
*Also* as a bonus - if there are blanks left in the bag - when I generated the list of words and tiles needed to play them, as well as generating 'retains' I would also have generated retAins, retainS, etc where each letter was made using the blank. So the standard probability calculation will provide the correct answer for using a blank, just by treating it as any other tile.
Now the helpful bit: although we could make this rack leave calculation using *every* word that can be placed - why not make it using only the list of words that can be placed which score over some particular amount that we're interested in. Similarly we could make a special rack-leave calculation that favoured only bingoes.
This first test deliberately used a very closed up board - which is exactly where lookahead gives you the most benefit - on an open board, there's not much to say except that your opponent can put just about anything anywhere, for just about any move you make. The only significant benefit I expect on an open board is avoidance of TW squares - or more precisely, knowing when it's safe to open up TW squares because some hook prohibits them from being used by your opponent.
Note: on an open board, the code is still useful because it very clearly identifies which parts of the board are 'hot' (ie easily used to place almost any word). This information can be used by the program if it has a heuristic about opening up or closing down the board, so the data from the global evaluation phase can be used in other ways apart from just the lookahead. For instance in this board, it pretty much correctly identified that the F7 down row forming a word ending in AL was one of the two most likely places for a bingo - if the player in the lead (up by 132 points at this juncture) had wanted to tighten the board up more, he would have used this info to play a blocking move that eliminated the possibility of using that hook. As it happens his opponent took advantage of that slot the very next move, and went on to slash the player's lead and went from 132 points down to 13 points ahead!
I do actually plan to make the lookahead work with open boards too, but not by enumerating every single play (where for instance all 7 letter words could be placed at a dozen different sites on the board (unless of course when I actually try the code it turns out to be counterintuitive in as much as it may be possible to calculate all those redundant words in a reasonable length of time after all...)) but by specifically identifying sites which are too open, and using an approximating probability formula to jump ahead straight to the answer, there being little point in enumerating 20,000 different ways you can add up to 70 for example. It is relatively easy to calculate the probability of a bingo given say 50 tiles left; indeed the likelihood of a bingo on the opening rack is already well known to regular Scrabble players.
An idea referred to earlier in this document may allow the next level of lookahead at a reduced cost. When examining the replies to your move, let's say there are 6000 possible words which can be played at F8 down in the example above. Instead of evaluating 6000 replies, one in response to each word, what we can do is place wild card tiles on the actual board and evaluate replies to a board which contains wild-cards. In this example, it should immediately show that there is a high probability of a word from A7 to F7 which scores triple. This information alone helps us, without the need to enumerate it 6000 times. [This shortcut is incidental to the central idea of this paper, and may be dropped in later revisions. Whether it is necessary or not depends solely on the speed of the computer running the Global Analysis] [Comment on this on-line]
There are a couple of places in the full listing above where there are open spaces abuting against a single letter, which generate a huge run of options all for the same square. These are the ones I would conflate with the calculation suggested above, as done here manually in the compacted listing. In the final version of this, the conflated strings will be annotated with the sum of the probabilities of all the individual moves which they have replaced, a count of the number of plays, and their average score.
(I am indebted to Harold Rennett (who goes by the handle of Tuchusfacius on the web - see his web page at Addicted To Words) - who has been teaching me the maths behind calculating probabilities relevant to Scrabble. Without his help this program would not be possible.)
It is obvious from the test that this technique is going to work, in enough real-life situations, that it is worth adding to the arsenal of Scrabble computer programs. I intend to develop it further over the coming weeks.
I believe this technique works best on closed boards and near the endgame; roughly the same areas as Monte Carlo but with higher confidence. (I also believe it can be switched to exhaustive search mode several moves earlier than current exhaustive lookahead allows, by virtue of the fact that one evaluation generates all possible replies and thus saves considerable CPU time and allows more evaluations.)
It has recently been pointed out to me that Scrabble program authors currently define the endgame as that point when there are no tiles in the bag and the racks can be played out with perfect knowlege. This is not what I consider the endgame - in my opinion, the endgame is when a full decision tree evaluation can be performed to exhaustion. This is certainly true when there are no tiles left to draw at all, but I believe it is also true when there is only a small number of tiles left to draw, depending on the board layout. Apparently current programs do not perform an exhaustive search even when there are no tiles left to draw. It may be that the branching ratios are simply too high, but my intuition says otherwise. Some coding and testing will remove this from the realm of speculation...If I were writing a competitive program today which used this technique, I would bias my playing of the mid game to deliberately close up the board at times, in order to allow this code more opportunity of an advantage by lookahead if playing an opponent who was not using lookahead or using Monte Carlo based lookahead (which would not, for example, have any chance of finding the SAX bingo extension above, but if it did hit it by luck, would assign more significance to the play than it deserves).
NOTE: It is possible to duplicate the standard Monte Carlo algorithm exactly using the results of the global analysis. For any given randomly selected rack, you can traverse the list of plays generated by the global analysis, and determine which plays are possible with the given rack. From that you will know the highest scoring play for that rack. This is a cheap operation compared to running a board evaluation from scratch (a suitable data structure will make it very cheap operation, but even a linear scan of the totality of generated moves would be much faster than a classic board evaluation - note: a good data structure for finding compatible racks if using a linear scan (of a list sorted in order of high score first) would be the 'signature' structure of Ars Magna), and therefore we can prove that this algorithm is at least as powerful as classic Monte Carlo because in the worst case - ignoring all the probability mathematics - it can be used simply as a much faster alternative to board evaluation for Monte Carlo.
- Graham Toal